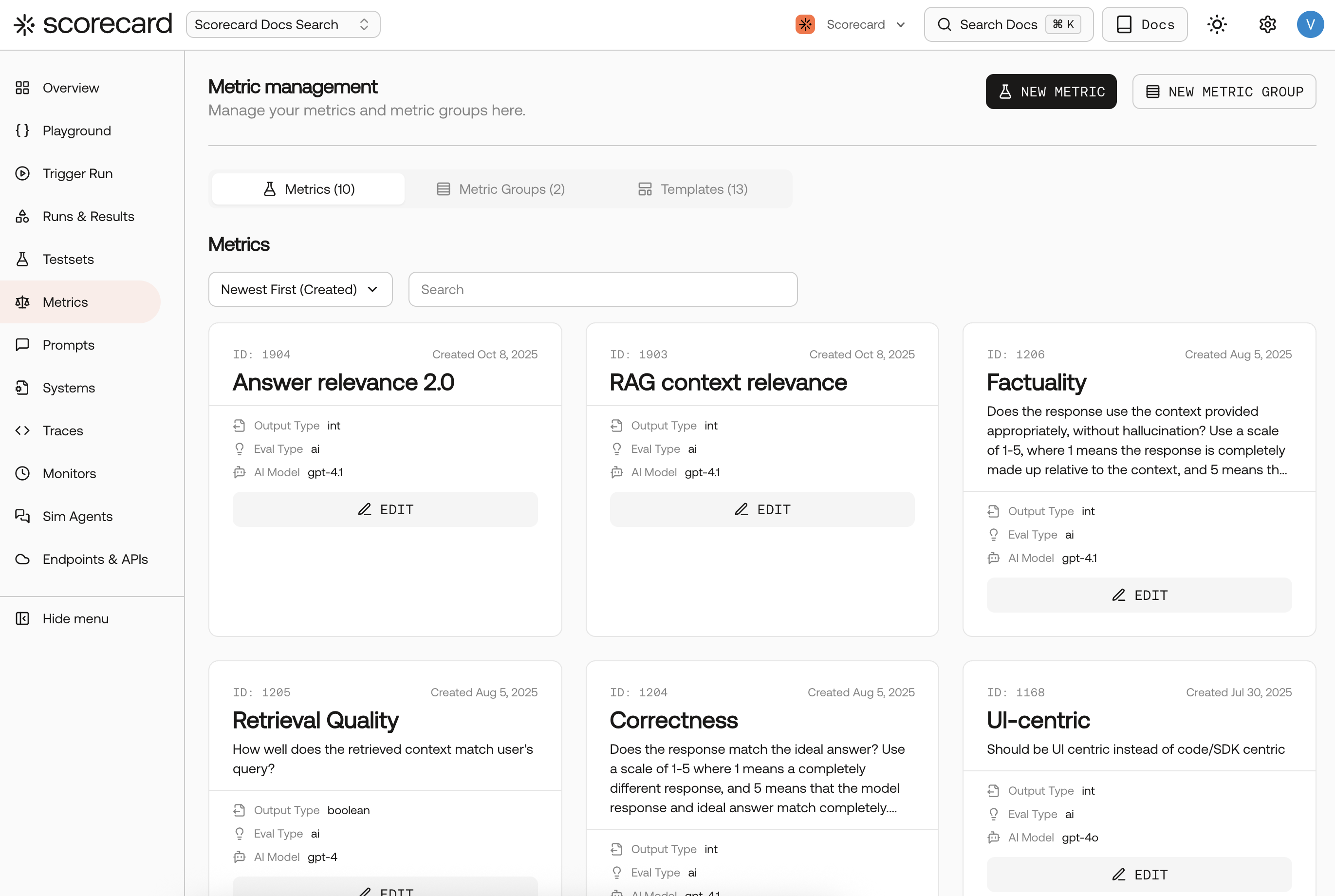
Open Metrics and explore templates
Go to your project’s Metrics page. Start fast by copying a proven template, then tailor the guidelines to your domain.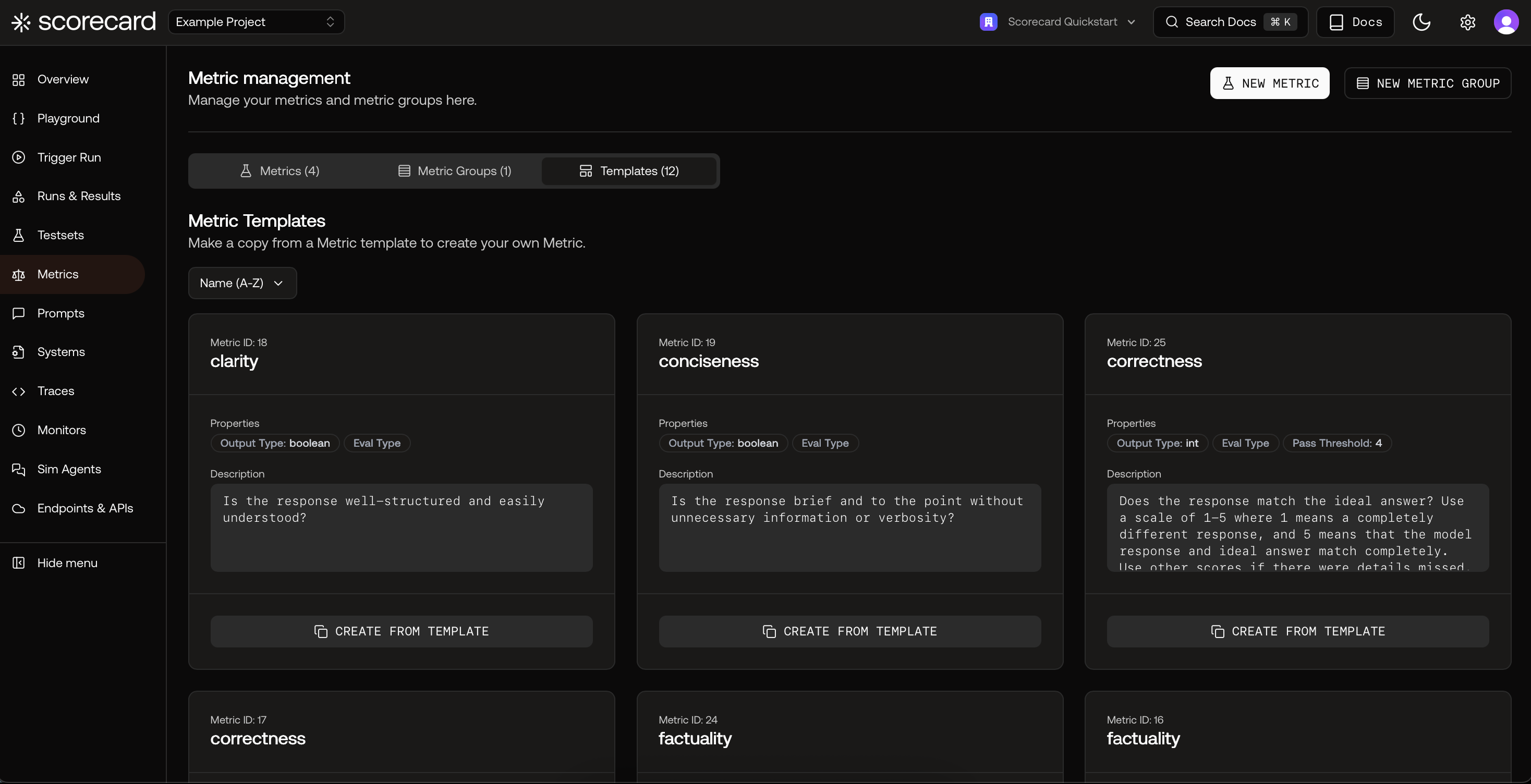
Create a metric
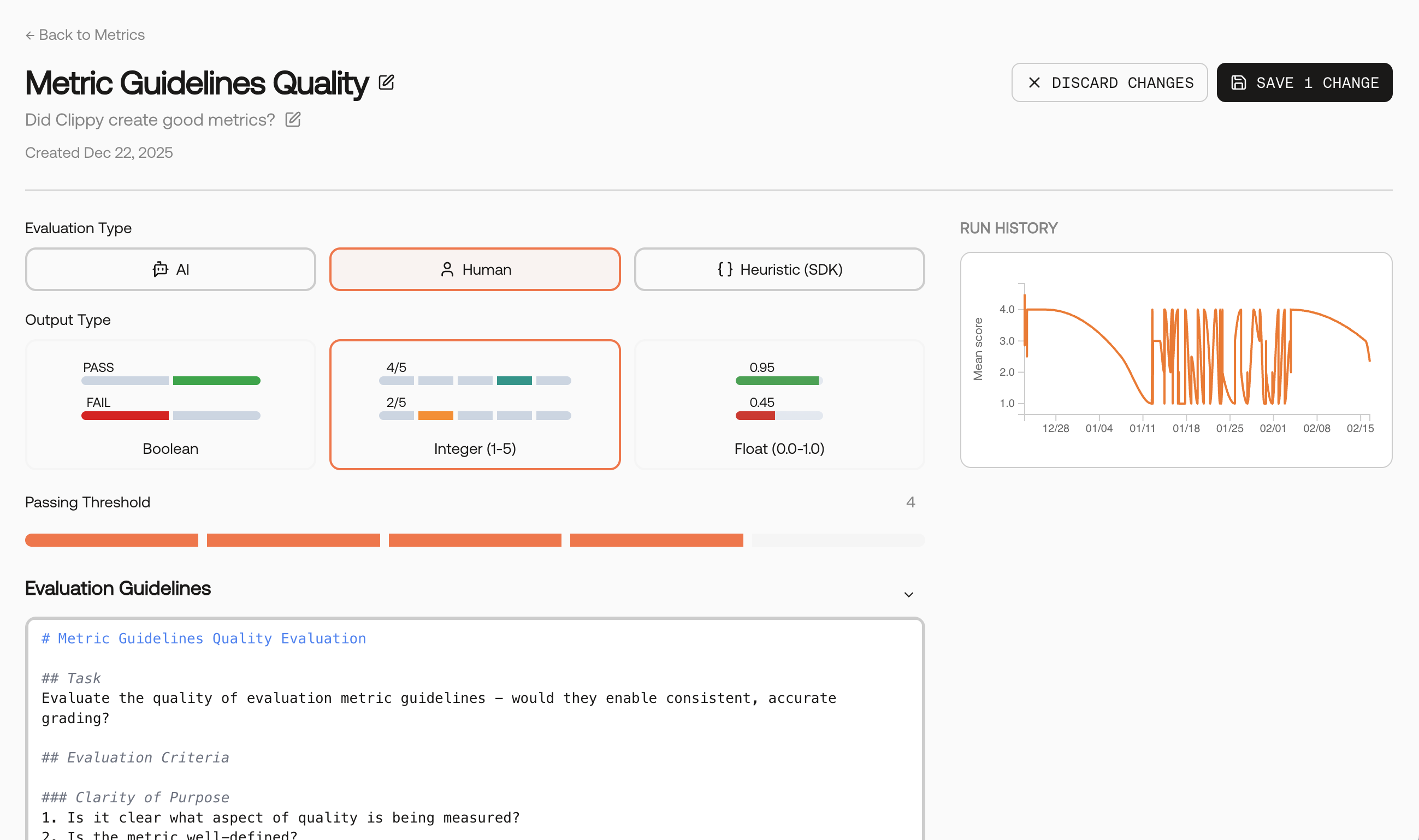
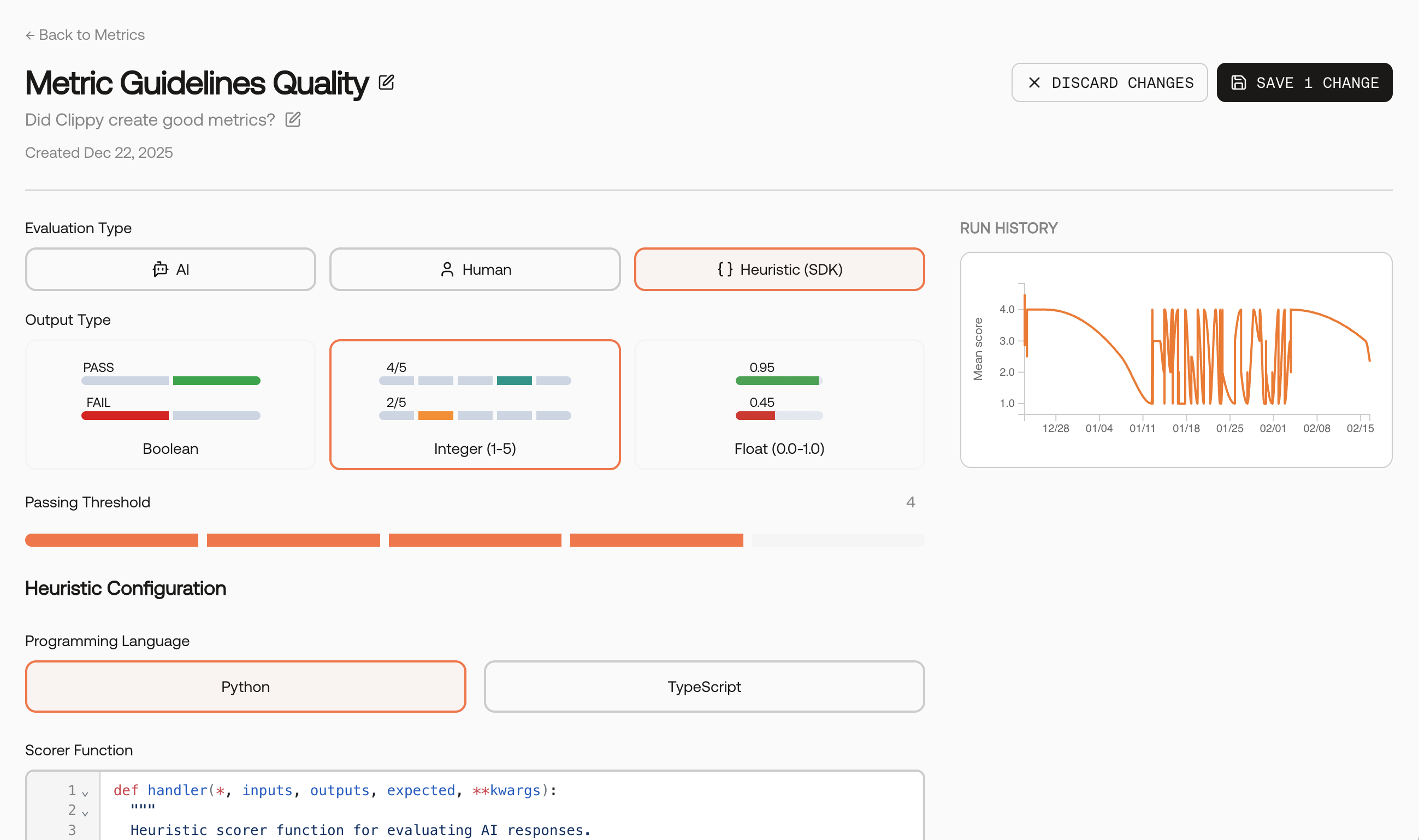
You can also create a metric from scratch. Provide a name, description, clear guidelines, and choose an Evaluation Type and Output Type.
Guidelines matter. Describe what to reward and what to penalize, and include 1–2 concise examples if helpful. These instructions become the core of the evaluator prompt.
- AI‑scored
- Human‑scored
- Heuristic (SDK)
- Critic Agent (coming soon)
Uses a model to apply your guidelines consistently and at scale. Pick the evaluator model and keep temperature low for repeatability.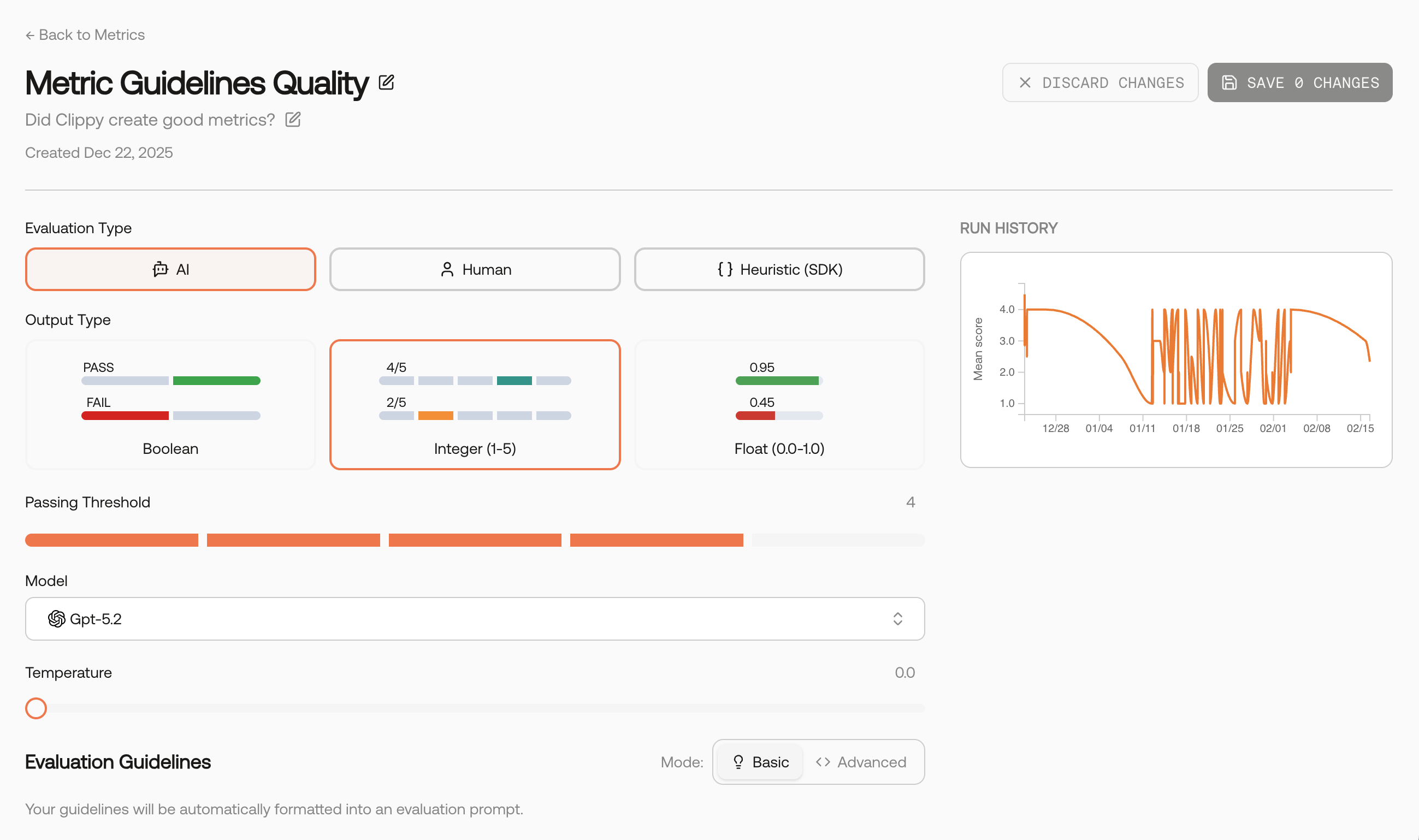
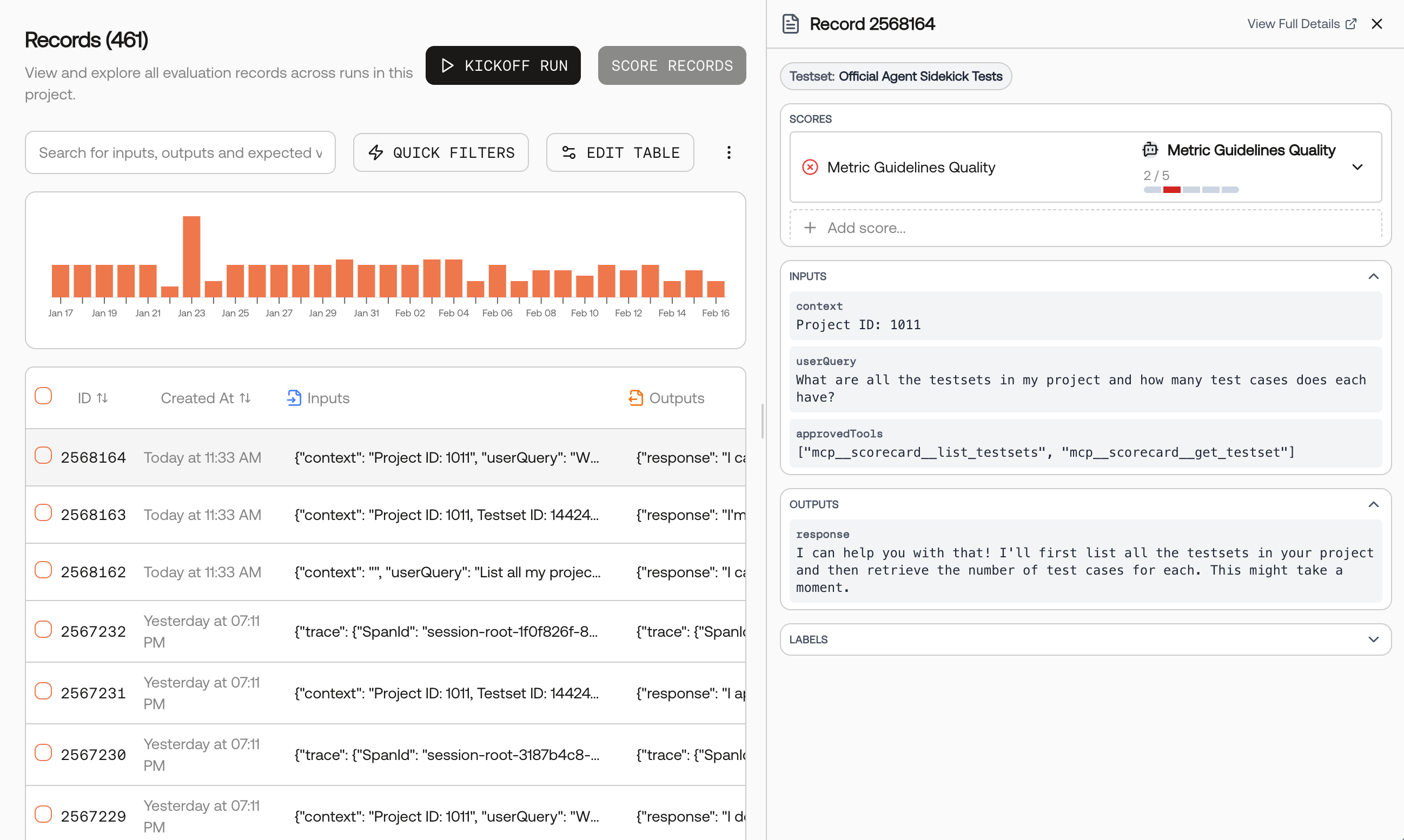
Go to the Records page and select records
Navigate to your project’s Records page. Select the records you want to score, then click the Score Records button.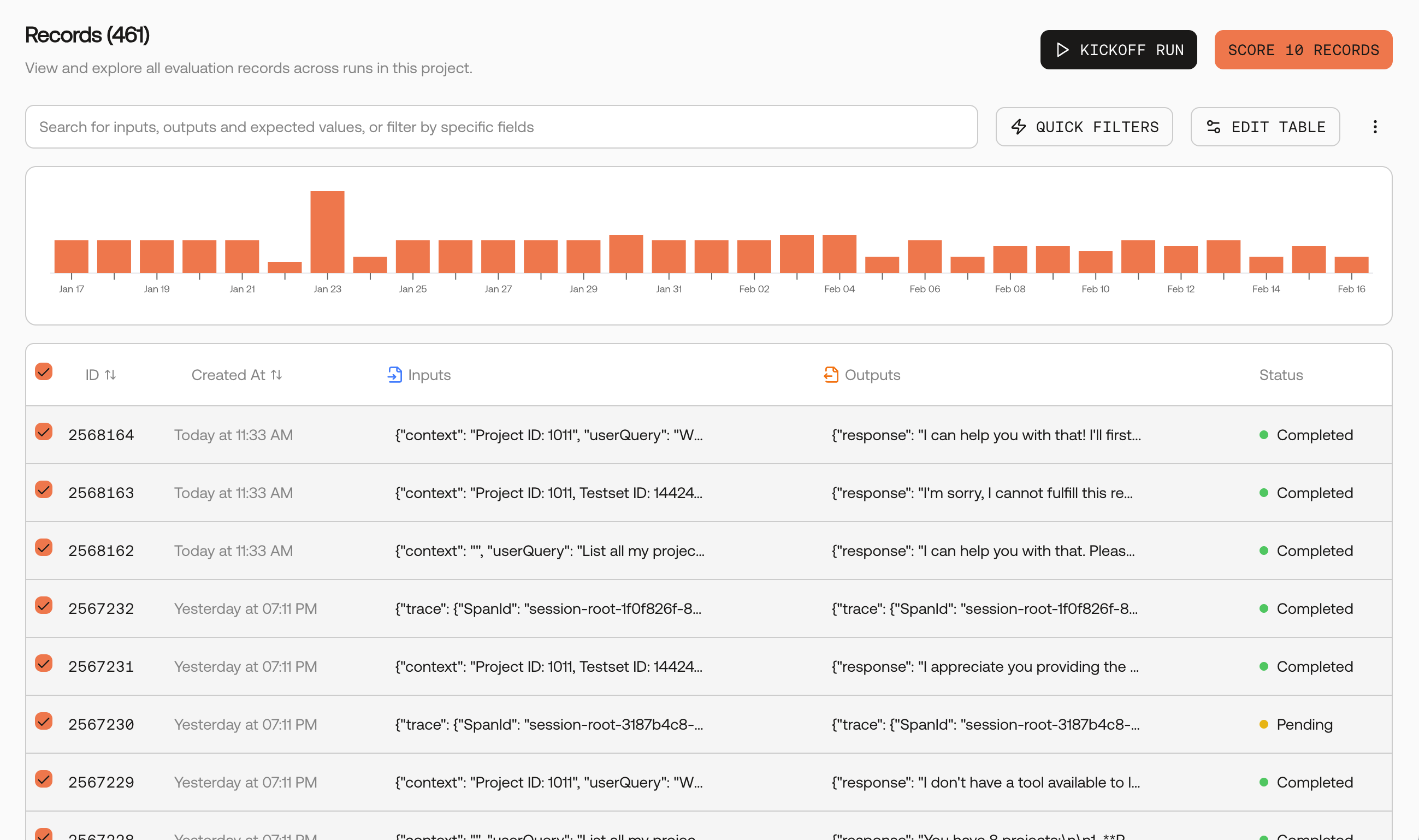
Choose metrics and score
In the Score Records modal, select one or more metrics to evaluate against, then click Score.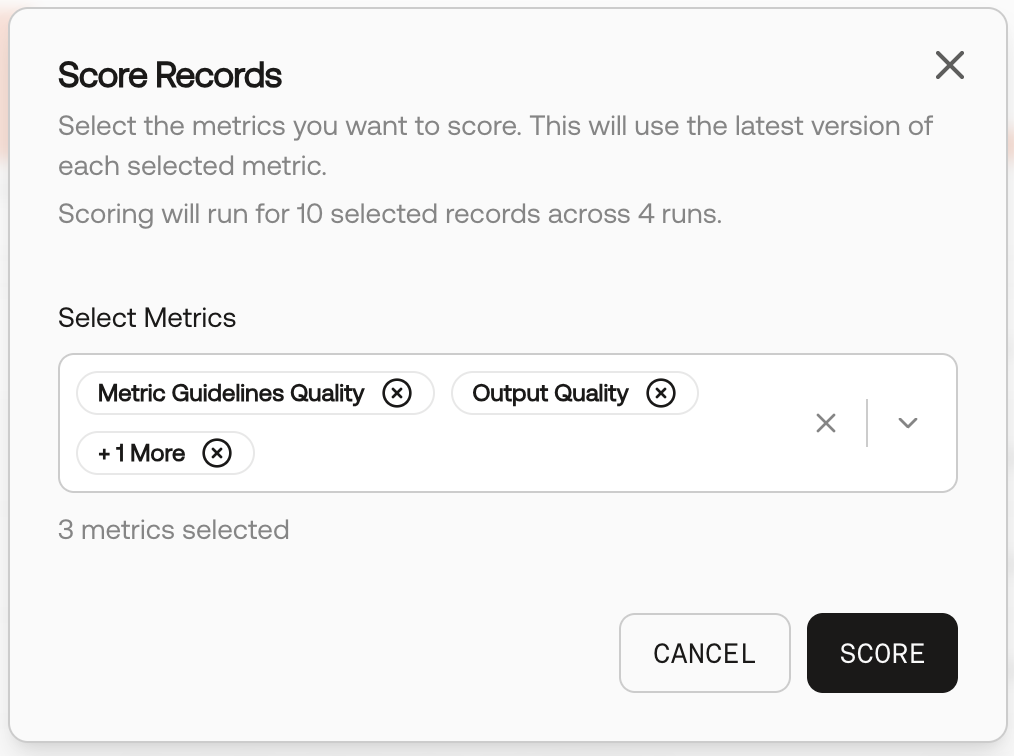
Metric types
- AI‑scored: Uses a model to apply your guidelines consistently and at scale.
- Human‑scored: Great for nuanced judgments or gold‑standard baselines.
- Heuristic (SDK): Deterministic, code‑based checks via the SDK (e.g., latency, regex, policy flags).
- Critic Agent (coming soon): An agentic evaluator that reasons over multiple steps with tool use.
- Output types: Choose Boolean (pass/fail) or Integer (1–5).
Second‑party metrics (optional)
If you already use established evaluation libraries, you can mirror those metrics in Scorecard:- MLflow genai: Relevance, Answer Relevance, Faithfulness, Answer Correctness, Answer Similarity
- RAGAS: Faithfulness, Answer Relevancy, Context Recall, Context Precision, Context Relevancy, Answer Semantic Similarity
Best practices for strong metrics
- Be specific. Minimize ambiguity in guidelines; include “what not to do.”
- Pick the right output type. Use Boolean for hard requirements; 1–5 for nuance.
- Keep temperature low. Use ≈0 for repeatable AI scoring.
- Pilot and tighten. Run on 10–20 cases, then refine wording to reduce false positives.
- Bundle into groups. Combine complementary checks (e.g., Relevance + Faithfulness + Safety) to keep evaluations consistent.
Looking for vetted, ready‑to‑use metrics? Explore Best‑in‑Class Metrics and copy templates (including MLflow and RAGAS). You can also create deterministic checks via the SDK using Heuristic metrics.
Related resources
Runs
Create and analyze evaluations
A/B Comparison
Compare two runs side‑by‑side
Best‑in‑Class Metrics
Explore curated, proven metrics
API Reference
Create metrics via API